Claude Opus 4.6: Anthropic's Next-Gen AI Model Raises the Bar on Reasoning and Code
Anthropic has released Claude Opus 4.6, featuring enhanced reasoning capabilities, improved code generation, and extended context windows. The new model represents a significant step forward in AI performance across multiple benchmarks.
The AI Reasoning Wars Just Got More Competitive
The frontier AI market is heating up. While competitors race to claim superiority in reasoning and code generation, Anthropic has released Claude Opus 4.6, a model that meaningfully advances its capabilities across multiple dimensions. This isn't just an incremental update—it's a strategic move to solidify Anthropic's position in the increasingly crowded space of advanced AI systems.
What's New in Claude Opus 4.6
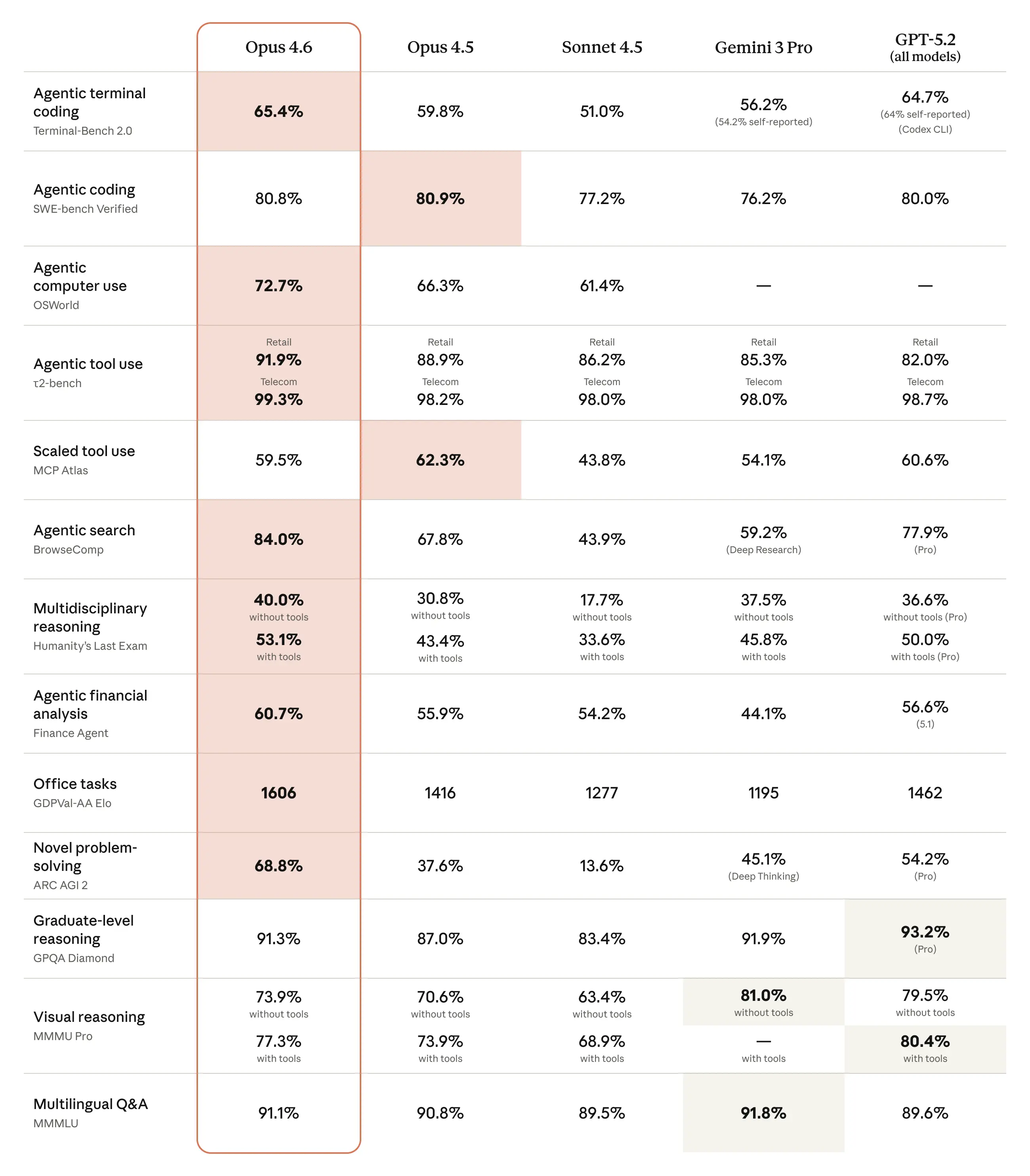
According to Anthropic's technical documentation, the latest iteration brings several substantive improvements:
Enhanced Reasoning and Problem-Solving The model demonstrates stronger performance on complex reasoning tasks, making it more capable of handling multi-step logical problems and nuanced analysis. This addresses a key competitive pressure point as enterprises demand AI systems that can tackle increasingly sophisticated challenges.
Improved Code Generation and Analysis Developers will find Claude Opus 4.6 more effective at writing, debugging, and analyzing code across multiple programming languages. The model shows measurable improvements in code quality and correctness, critical for engineering teams relying on AI-assisted development.
Extended Context Window The expanded context window allows the model to process and retain information from longer documents and conversations, reducing the friction of working with large codebases or comprehensive research materials.
Better Instruction Following The model exhibits improved adherence to nuanced instructions and constraints, making it more reliable for specialized tasks where precision matters.
Performance Metrics and Benchmarks
Technical analysis from industry observers indicates that Claude Opus 4.6 shows competitive performance across standard AI benchmarks. The improvements are particularly pronounced in:
- Complex reasoning tasks requiring multi-hop inference
- Code generation and software engineering workflows
- Long-context document analysis and synthesis
- Instruction-following accuracy in constrained scenarios
These gains matter because they directly translate to real-world utility. A developer using Claude Opus 4.6 for code generation will experience fewer iterations and higher-quality outputs. A researcher processing lengthy documents will get more accurate summaries and analysis.
Market Implications
The release reflects Anthropic's commitment to the "scaling laws" approach—the belief that larger, better-trained models with improved architectures will continue to outperform their predecessors. This contrasts with some competitors' emphasis on specialized fine-tuning or novel architectures.
For enterprises evaluating AI platforms, Claude Opus 4.6 raises the baseline expectations for what "frontier" AI should deliver. It's particularly relevant for organizations in software development, research, and complex analysis workflows where reasoning quality directly impacts outcomes.
Availability and Integration
The model is available through Anthropic's platform and integrated into their API offerings. Developers can access it through standard Claude API endpoints, making adoption straightforward for teams already using Anthropic's infrastructure.
The Bigger Picture
Claude Opus 4.6 doesn't represent a revolutionary leap in AI capabilities—it's an evolutionary step that consolidates Anthropic's technical advantages. In a market where multiple players claim "best-in-class" reasoning, the company is backing up that claim with measurable improvements across multiple dimensions.
The real test will be adoption. How quickly will enterprises migrate workloads to the new model? Will the improvements justify retraining and reoptimization efforts? These questions will determine whether Claude Opus 4.6 becomes a standard tool in AI-powered workflows or remains another incremental release in an increasingly crowded field.
For now, it's clear that Anthropic is not standing still—and neither should its competitors.



