OpenAI Launches FrontierScience Benchmark to Evaluate Advanced AI Scientific Reasoning
OpenAI introduces FrontierScience, a comprehensive benchmark designed to assess the scientific reasoning and problem-solving capabilities of frontier AI models, marking a significant step in standardizing AI evaluation across research domains.
OpenAI Launches FrontierScience Benchmark to Evaluate Advanced AI Scientific Reasoning
OpenAI has introduced FrontierScience, a new benchmark designed to rigorously evaluate the scientific reasoning capabilities of artificial intelligence systems. The benchmark represents a significant effort to establish standardized metrics for assessing how well AI models can tackle complex scientific problems across multiple disciplines.
What Is FrontierScience?
FrontierScience is a comprehensive evaluation framework that tests AI models' ability to reason through scientific challenges, understand domain-specific knowledge, and apply logical problem-solving approaches to research-oriented tasks. The benchmark encompasses problems spanning physics, chemistry, biology, mathematics, and other scientific domains, providing a holistic view of an AI system's scientific comprehension.
The benchmark is structured to move beyond simple factual recall, instead focusing on:
- Multi-step reasoning: Problems requiring sequential logical steps and intermediate conclusions
- Domain expertise: Tasks demanding specialized knowledge across scientific disciplines
- Novel problem-solving: Challenges that test generalization and creative application of scientific principles
- Quantitative analysis: Evaluation of mathematical reasoning and data interpretation capabilities
Why This Matters for AI Development
The introduction of FrontierScience addresses a critical gap in AI evaluation methodologies. While existing benchmarks measure general knowledge and language understanding, they often fall short in assessing the nuanced reasoning required for scientific research and discovery. This benchmark provides researchers with a more precise tool for understanding where frontier AI models excel and where they require improvement.
For the AI research community, standardized scientific reasoning benchmarks are essential for:
- Tracking progress in AI capabilities over time
- Identifying specific weaknesses in model reasoning
- Guiding development priorities for next-generation systems
- Enabling fair comparison between different AI architectures and approaches
Implications for AI Research
The release of FrontierScience signals OpenAI's commitment to transparency and rigorous evaluation standards. By making such benchmarks available to the research community, OpenAI contributes to the broader effort of understanding and improving AI systems' capabilities in specialized domains.
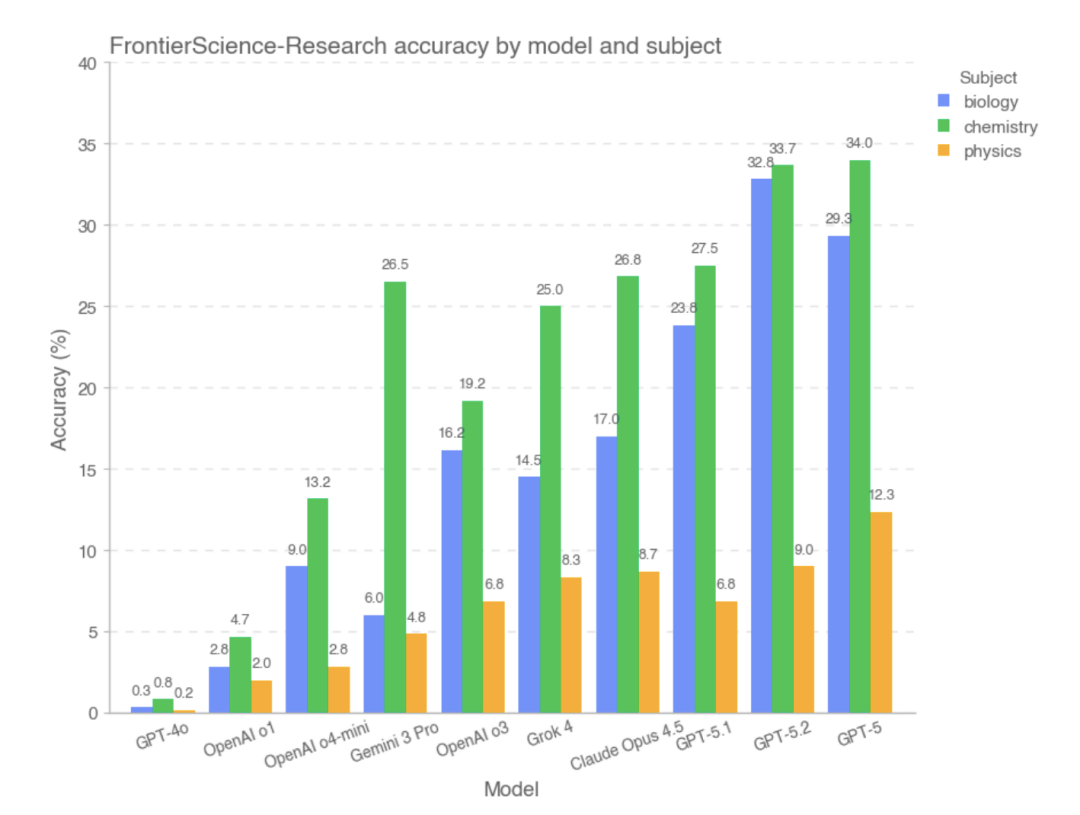
Early results from FrontierScience testing indicate that frontier AI models demonstrate varying levels of proficiency across different scientific domains. Some models show particular strength in mathematical reasoning and physics problems, while others demonstrate more balanced performance across disciplines. These findings help researchers understand the current state of AI scientific reasoning and inform future development efforts.
The benchmark also serves as a tool for identifying potential biases or gaps in AI training data, particularly in specialized scientific fields where comprehensive training datasets may be limited or uneven in coverage.
Looking Forward
As AI systems become increasingly integrated into scientific research workflows—from drug discovery to materials science—the ability to accurately assess their scientific reasoning becomes paramount. FrontierScience represents one step in this direction, though the field will likely continue developing more specialized benchmarks for specific scientific domains and applications.
The benchmark's introduction also highlights the broader conversation around AI evaluation standards. As AI capabilities advance, the research community must continually develop more sophisticated assessment tools to ensure that progress can be accurately measured and understood.
Key Sources
- OpenAI's official announcements and technical documentation on FrontierScience benchmark specifications
- Research publications detailing benchmark methodology and initial evaluation results
- Industry analysis of AI evaluation standards and their role in advancing frontier AI capabilities
About This Evaluation Framework: FrontierScience joins a growing ecosystem of AI benchmarks designed to measure specific capabilities. Its focus on scientific reasoning provides valuable insights into how current AI systems approach domain-specific challenges and where future improvements may be needed.



