Dots.OCR: The Vision-Language Model Reshaping Multilingual Document Parsing
Dots.OCR emerges as a powerful vision-language model designed to parse complex document layouts across multiple languages, challenging the dominance of proprietary solutions in document AI.
The Document AI Arms Race Heats Up
The race to dominate document intelligence is intensifying. While enterprise giants have long controlled the market with expensive, proprietary solutions, a new generation of open-source vision-language models is disrupting the landscape. Dots.OCR represents a significant step forward—a multilingual document layout parser built on modern VLM architecture that promises to democratize access to sophisticated document processing capabilities.
The timing is critical. Organizations worldwide are drowning in unstructured documents—invoices, contracts, forms, and reports in dozens of languages. Traditional OCR systems struggle with layout complexity, while proprietary solutions demand steep licensing fees. Dots.OCR enters this gap with an open-source alternative designed to handle the real-world messiness of document parsing at scale.
Understanding the Technical Foundation
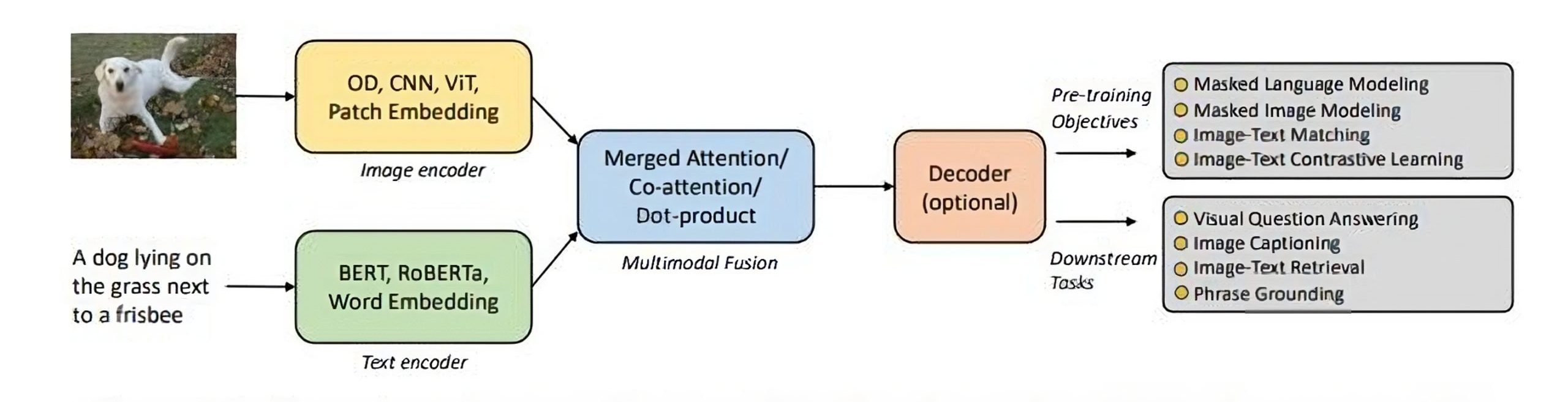
Dots.OCR leverages vision-language model architecture to move beyond simple text extraction. Rather than treating documents as flat sequences of characters, the system understands spatial relationships, hierarchical structures, and semantic meaning within layouts.
According to research on document AI approaches, modern document parsing requires three core capabilities:
- Layout Detection: Identifying regions, tables, headers, and content blocks
- Reading Order: Determining the logical sequence of information extraction
- Multilingual Support: Processing documents in non-Latin scripts and diverse languages
Dots.OCR addresses all three by combining visual understanding with language-agnostic processing. The model can recognize document structure without relying on language-specific heuristics, making it genuinely multilingual rather than simply supporting multiple language packs.
The Competitive Landscape
The document AI space has shifted dramatically. Recent analysis of open VLM-based OCR solutions shows that 2024-2025 marks an inflection point where open-source models begin matching proprietary alternatives in accuracy while offering superior flexibility and cost efficiency.
Dots.OCR's open-source nature creates several advantages:
- Customization: Organizations can fine-tune the model for domain-specific documents
- Transparency: No black-box processing; teams understand exactly how documents are parsed
- Cost: Eliminates recurring licensing fees for document processing infrastructure
- Community Development: Collaborative improvements from researchers and practitioners worldwide
Technical Architecture and Capabilities
The arxiv paper detailing Dots.OCR's architecture reveals a system designed for real-world complexity. Rather than assuming clean, well-formatted documents, the model handles:
- Scanned documents with variable quality and rotation
- Complex table structures with merged cells and irregular layouts
- Mixed-language documents where text switches between writing systems
- Handwritten annotations and marginal notes
The system achieves this through a two-stage approach: first identifying document structure and regions, then extracting and understanding content within those regions. This mirrors how humans parse documents—we first understand the layout, then read the content.
Practical Implementation and Adoption
For teams considering deployment, video demonstrations show Dots.OCR handling real-world scenarios: financial statements with complex tables, multilingual contracts, and forms with irregular layouts. The results suggest accuracy rates competitive with enterprise solutions while maintaining the flexibility of open-source software.
The model's multilingual capabilities are particularly significant for global operations. Rather than maintaining separate pipelines for different languages, organizations can deploy a single system that understands document structure across linguistic boundaries.
What This Means for Document Processing
Dots.OCR signals a broader shift in document AI: the commoditization of core capabilities. As open-source models mature, competitive advantage moves from basic parsing to specialized applications—industry-specific fine-tuning, integration with downstream AI systems, and custom workflow automation.
Organizations that have delayed document automation due to cost or vendor lock-in concerns now have a credible alternative. The real question isn't whether to adopt document AI, but whether to build on proprietary platforms or leverage the growing ecosystem of open-source tools.



