OpenAI's GPT-5.4 Mini and Nano Models Challenge the Efficiency Frontier
OpenAI releases GPT-5.4 mini and nano models, delivering significant performance gains in smaller form factors. These new models promise faster inference and lower costs while maintaining competitive reasoning capabilities across benchmarks.
The Efficiency Race Heats Up
The AI market's obsession with scale is colliding head-on with the economics of deployment. OpenAI has released GPT-5.4 mini and nano models, marking a strategic pivot toward smaller, faster, and cheaper alternatives that don't sacrifice capability. This move directly challenges competitors racing to optimize their own compact models—a battleground where latency and cost-per-inference matter as much as raw intelligence.
The timing is significant. As enterprises grapple with the operational costs of running large language models at scale, the industry is bifurcating: full-capability flagships for complex reasoning, and efficient smaller models for the 80% of tasks that don't require maximum power. OpenAI's new lineup suggests the company is betting heavily on this split.
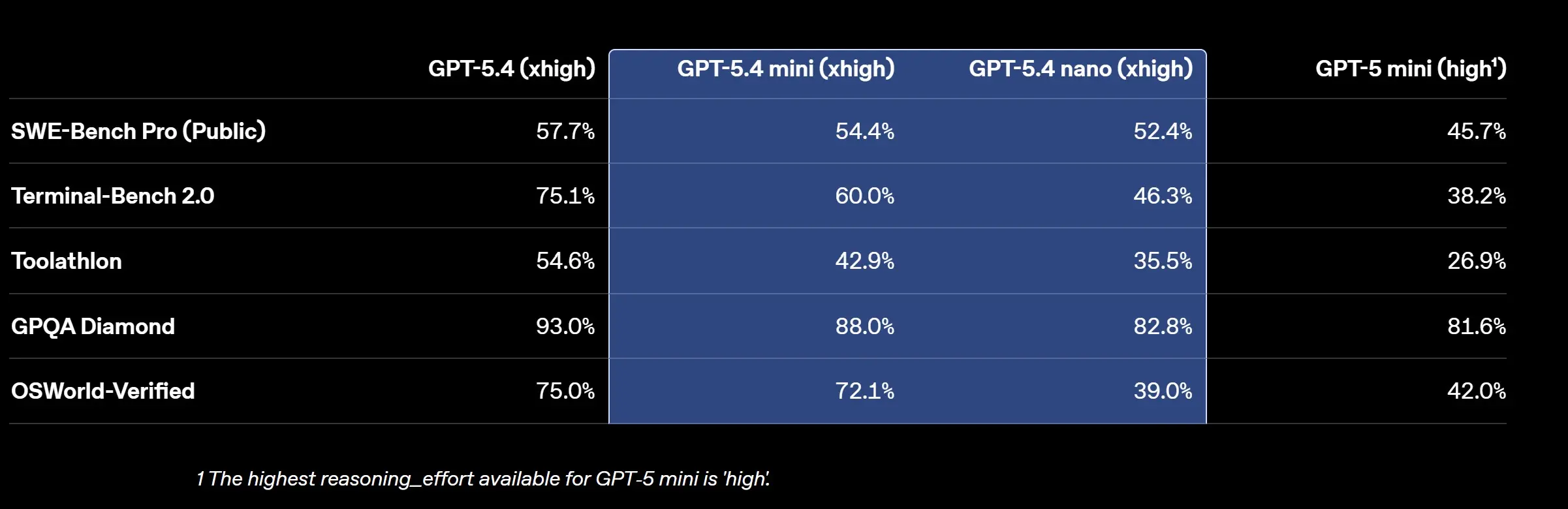
Performance Metrics: The Numbers Tell the Story
According to OpenAI's technical documentation, the GPT-5.4 mini and nano models demonstrate measurable improvements over their predecessors:
- GPT-5.4 mini achieves 54.4% on SWE-Bench Pro (software engineering benchmarks), compared to 45.7% for GPT-5 mini
- GPT-5.4 nano reaches 52.4% on the same benchmark, a substantial jump from earlier generations
- Both models show competitive performance on reasoning tasks like GPQA Diamond, with nano scoring 82.8%
The benchmark comparison chart reveals the performance hierarchy: the full GPT-5.4 remains the leader, but the gap between mini and nano variants has narrowed considerably.
What This Means for Developers and Enterprises
The practical implications are substantial. As reported by 9to5Mac, these models are optimized for:
- Lower latency: Faster response times for real-time applications
- Reduced infrastructure costs: Smaller models consume less compute, lowering operational expenses
- Edge deployment: Nano models can run on resource-constrained devices
- High-volume inference: Cost-effective scaling for applications processing millions of requests
According to 9to5Google's coverage, the nano model in particular targets use cases where speed and efficiency trump maximum capability—customer support chatbots, content moderation, and lightweight automation tasks.
The Competitive Landscape
This release positions OpenAI directly against Google's Gemini 2.0 Flash and Anthropic's Claude Haiku, both of which have emphasized efficiency. The mini/nano strategy also reflects lessons from the broader market: not every task requires GPT-5.4's full computational overhead.
OpenAI's official announcement emphasizes that these models represent a new generation of capability at smaller scales, suggesting the company views this as a fundamental architectural improvement rather than a simple parameter reduction.
Bottom Line
The release of GPT-5.4 mini and nano models signals that the AI industry's next frontier isn't about building bigger models—it's about building smarter, leaner ones. For enterprises evaluating deployment strategies, these new options expand the toolkit considerably, offering genuine performance gains in the efficiency tier where most real-world workloads actually live.



