Scaling LLM Training: How Parallel-Agent Reinforcement Learning Changes the Game
Parallel-Agent Reinforcement Learning is transforming how researchers train language models, enabling faster convergence and more efficient exploration of policy spaces through distributed agent coordination.
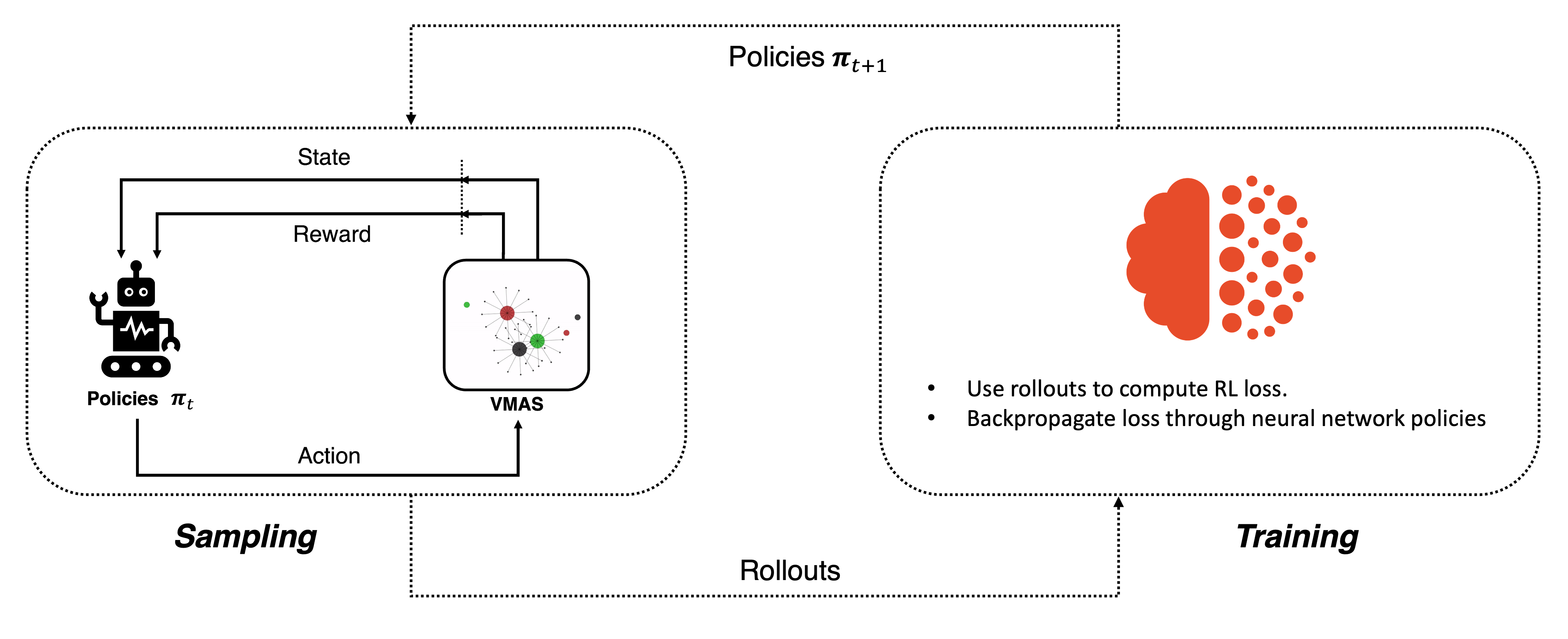
The Race to Smarter Training Methods
The competition to build more capable language models has shifted from raw compute power to algorithmic efficiency. While traditional reinforcement learning approaches train a single agent sequentially, a new paradigm is emerging: parallel-agent reinforcement learning that deploys multiple agents simultaneously to explore and learn from the same environment. This architectural shift promises to accelerate convergence, reduce sample inefficiency, and unlock new possibilities for LLM alignment and reasoning.
What Is Parallel-Agent Reinforcement Learning?
At its core, parallel-agent RL distributes the learning process across multiple agents operating concurrently. Rather than one agent collecting experience and updating its policy sequentially, multiple agents explore different trajectories in parallel, then aggregate their learnings. Recent research demonstrates that this approach significantly improves data efficiency and reduces wall-clock training time.
The key advantages include:
- Faster convergence: Multiple agents exploring simultaneously cover more of the policy space
- Reduced variance: Aggregating experiences from parallel agents stabilizes gradient estimates
- Better generalization: Diverse exploration patterns help models generalize to unseen scenarios
- Scalability: The approach naturally distributes across multiple GPUs and TPUs
Practical Implementation and Real-World Applications
Prime Intellect's analysis breaks down how parallel-agent RL applies directly to language model training. Instead of training one LLM policy sequentially, teams can spawn multiple model instances that explore different reasoning paths, reward signals, or prompt variations simultaneously. Each agent generates trajectories, receives feedback, and contributes to a shared policy update.
Amazon Science's work on multi-turn AI agents illustrates a concrete use case: training conversational agents that must maintain context across multiple turns. Parallel agents can simultaneously explore different dialogue strategies, allowing the base model to learn which conversation patterns maximize user satisfaction or task completion.
The Technical Landscape
The field is moving rapidly. Recent 2025 research papers highlight innovations in distributed policy optimization and environment design. Semi-Analysis newsletter coverage notes that RL environments themselves are becoming more sophisticated, enabling researchers to test parallel-agent approaches on complex reasoning tasks, scientific discovery, and code generation.
The infrastructure challenge remains significant. Coordinating multiple agents requires careful synchronization, efficient communication between processes, and robust gradient aggregation. However, frameworks like TorchRL are maturing to support these workflows natively.
Why This Matters Now
Language models trained with parallel-agent RL can achieve better performance on reasoning benchmarks, alignment tasks, and multi-step problem-solving. The approach also reduces the total computational cost per unit of performance improvement—a critical metric as model sizes continue to grow.
Simon Willison's coverage of parallel-agent developments notes that this technique is particularly valuable for fine-tuning existing models rather than training from scratch, making it accessible to organizations without unlimited compute budgets.
The Path Forward
Parallel-agent reinforcement learning represents a fundamental shift in how the industry approaches LLM optimization. As researchers continue refining these methods, expect to see faster iteration cycles, more efficient use of compute resources, and models that reason more effectively across complex domains. The next generation of state-of-the-art LLMs will likely owe their capabilities not just to scale, but to smarter training algorithms running in parallel.



